
For the ongoing exhibition (Dec21~Feb22) at the National Museum of Modern and Contemporary Art (MMCA), I researched and tested various generative adversarial networks (GANs) and methods on their inversion to create a desirable latent walk program. In this blog series, I’ll like to share and summarize papers I read for the project. In particular, I investigate applications using StyleGAN.
Overview
Generative adversarial network (GAN) is one of several methods that synthesize image samples from the high-dimensional data distribution. Typically, GAN consists of two networks: generator and discriminator. The goal of a generator is to produce a sample image indistinguishable from the training dataset, while the discriminator assesses generated images. While GAN is able to produce sharper images in comparison to other generative models such as VAE or autoregressive models they are limited in resolution and variation.
Despite improvements over the years on GAN, they are limited in resolution and variation. Training to produce high-resolution images is difficult with the traditional setup of GAN. A high resolution makes it easier for discriminators to identify as fake, amplifying the gradient problem. A larger resolutions force using smaller mini-batches during training time due to memory constraints. Furthermore, there is little understanding of the various aspects of the image synthesis process and the properties of the latent space that make GAN output controllable.
Here, we will specifically explore StyleGANs, a state-of-the-art image synthesis model, and how they overcome limitations and generate high-quality high-fidelity images.
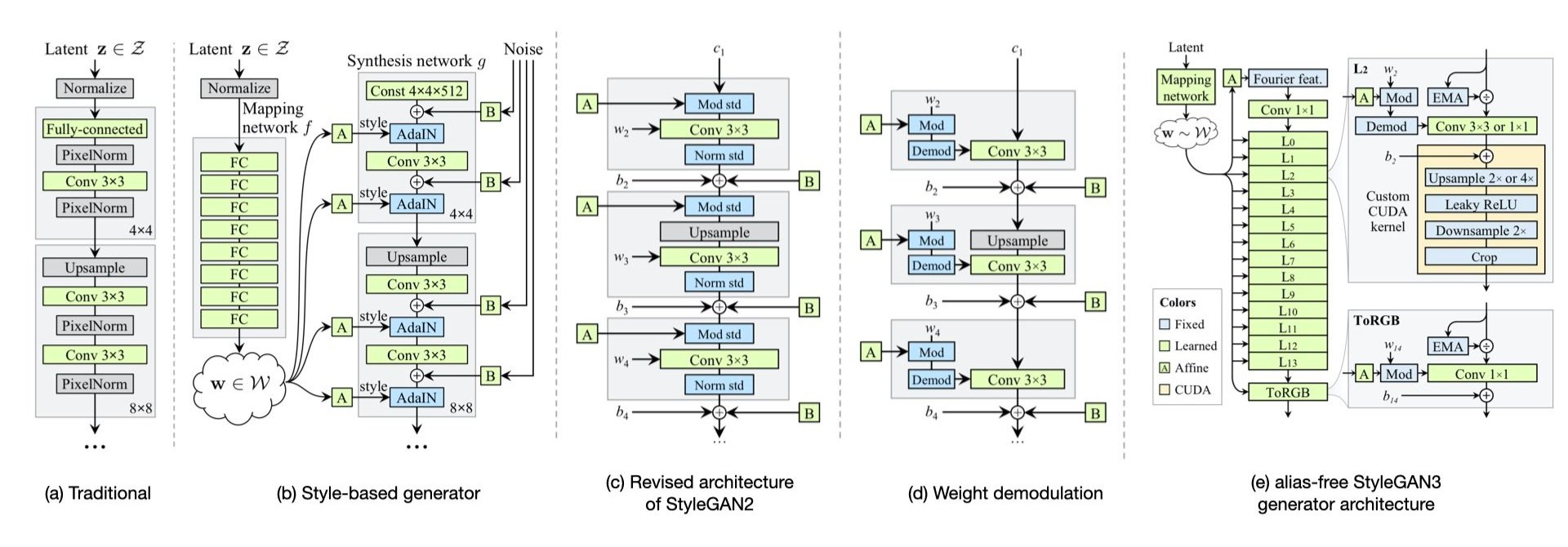
Figure1. Architectures of StyleGANs over its development [1,2,3]
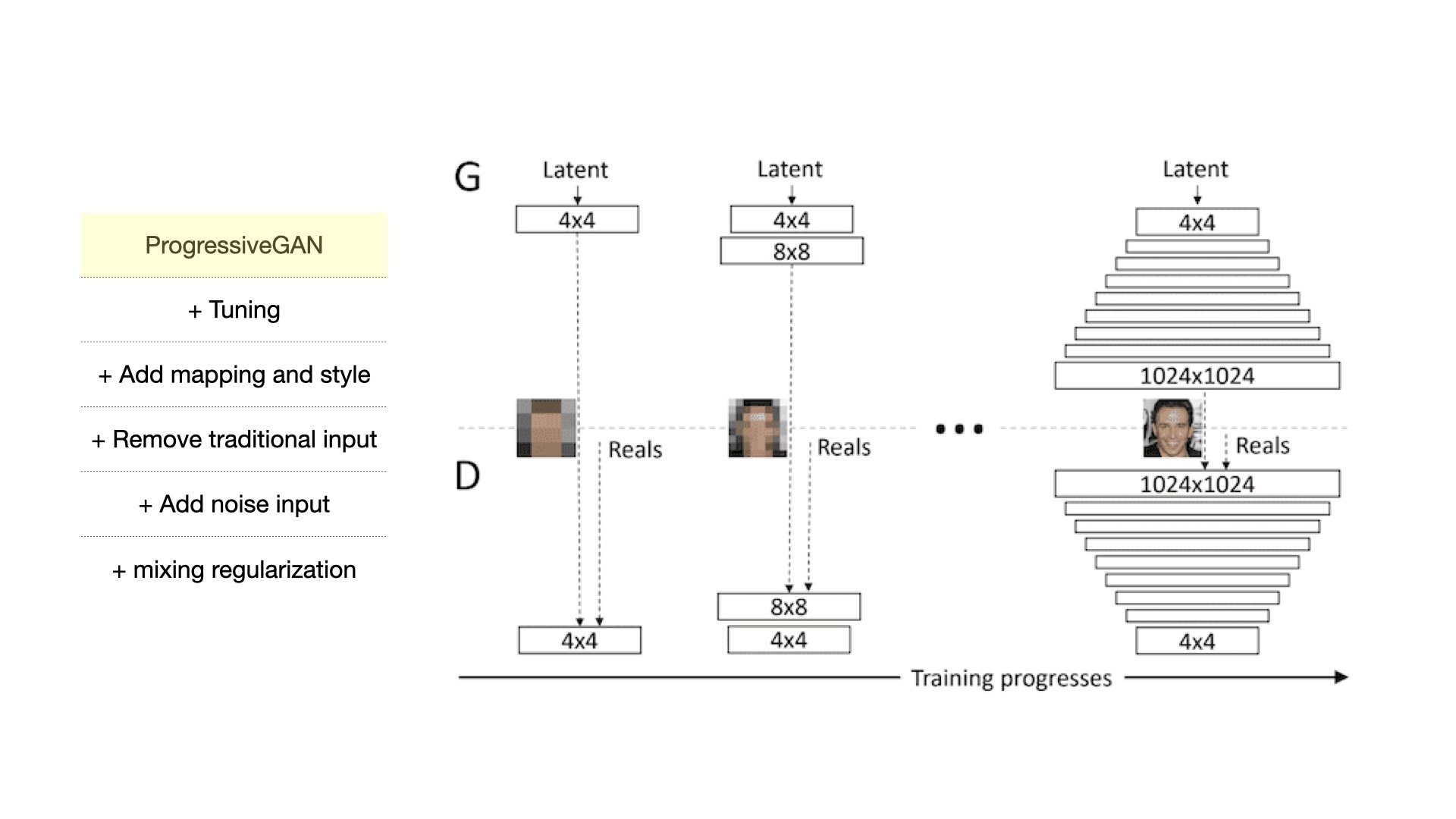
The author proposes a new architecture borrowing from a style transfer literature (i.e., ProgressiveGAN) that generates a high-resolution image and learns a hierarchy of attributes (high-level, like poses, from stochastic variables like hairs and freckles) in an unsupervised fashion.
Table1 summarizes additional components inserted by the authors to the baseline. Table2 displays the improvements associated with each factor.

Table1. Components of StyleGAN over its development. [1,2,3]
Metrics
In order to evaluate and understand the performance of GAN models, the authors defined the following new metrics in the paper.
Path Length a perceptually-based pairwise image distance is a weighted difference between two VGG16 embeddings. The weights are fit so that metric agrees with human perceptual similarity judgments. The latent space interpolation paths were subdivided into linear segments. Then the sum of all perceptual differences over each linear segment is the total perceptual length of this segmented path. Lower values indicate better image quality and GAN latent space entanglement.
EQ-T / EQ-R the peak signal-to-noise ratio (PSNR) in decibels (dB) between two sets of images, obtained by translating the input and output of the synthesis network by random amount. Each pair of images corresponds to a different random choice of w. EQ-R is computed similar to EQ-T but with rotation angles drawn from U(0,360)
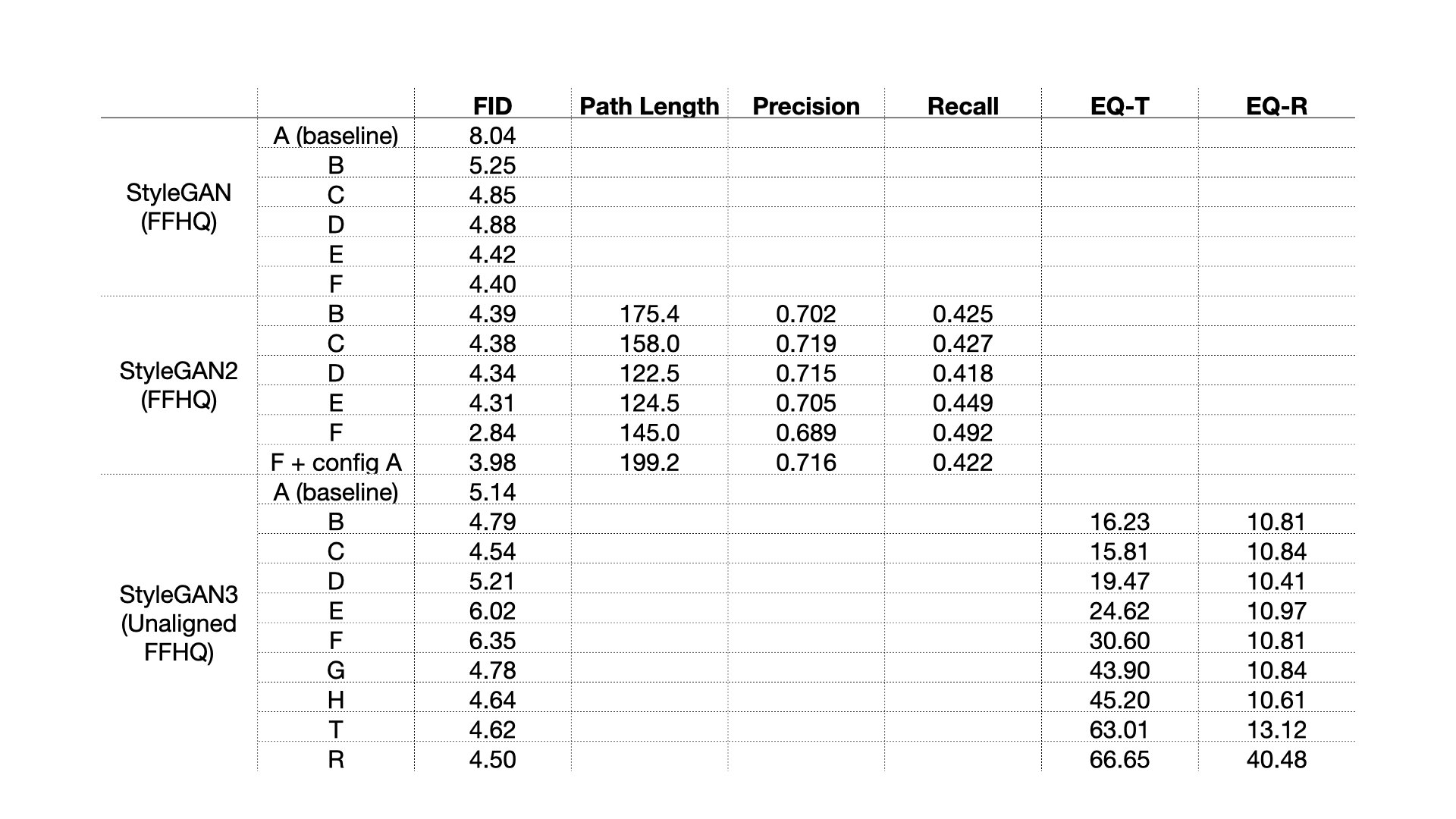
Table2. Scores presented in papers on FFHQ dataset [1,2,3]
StyleGAN
Typically, the generator takes a learnable latent vector, z, as an input and samples an image similar to the distribution of a training dataset. The image synthesis process of StyleGAN instead starts with a learned constant z. A mapping network (an eight-layer multi-layer perceptron (MLP) then transforms z into an intermediate latent code, w, which is inputted multiple times into each layer of GAN. The model becomes more controllable through better disentanglement of the latent factors in space.
Then, a spatially invariant style y, which corresponds to a scale and a bias parameter of the AdaIN layer (explained later), is computed from a vector w through a learned affine transformation.
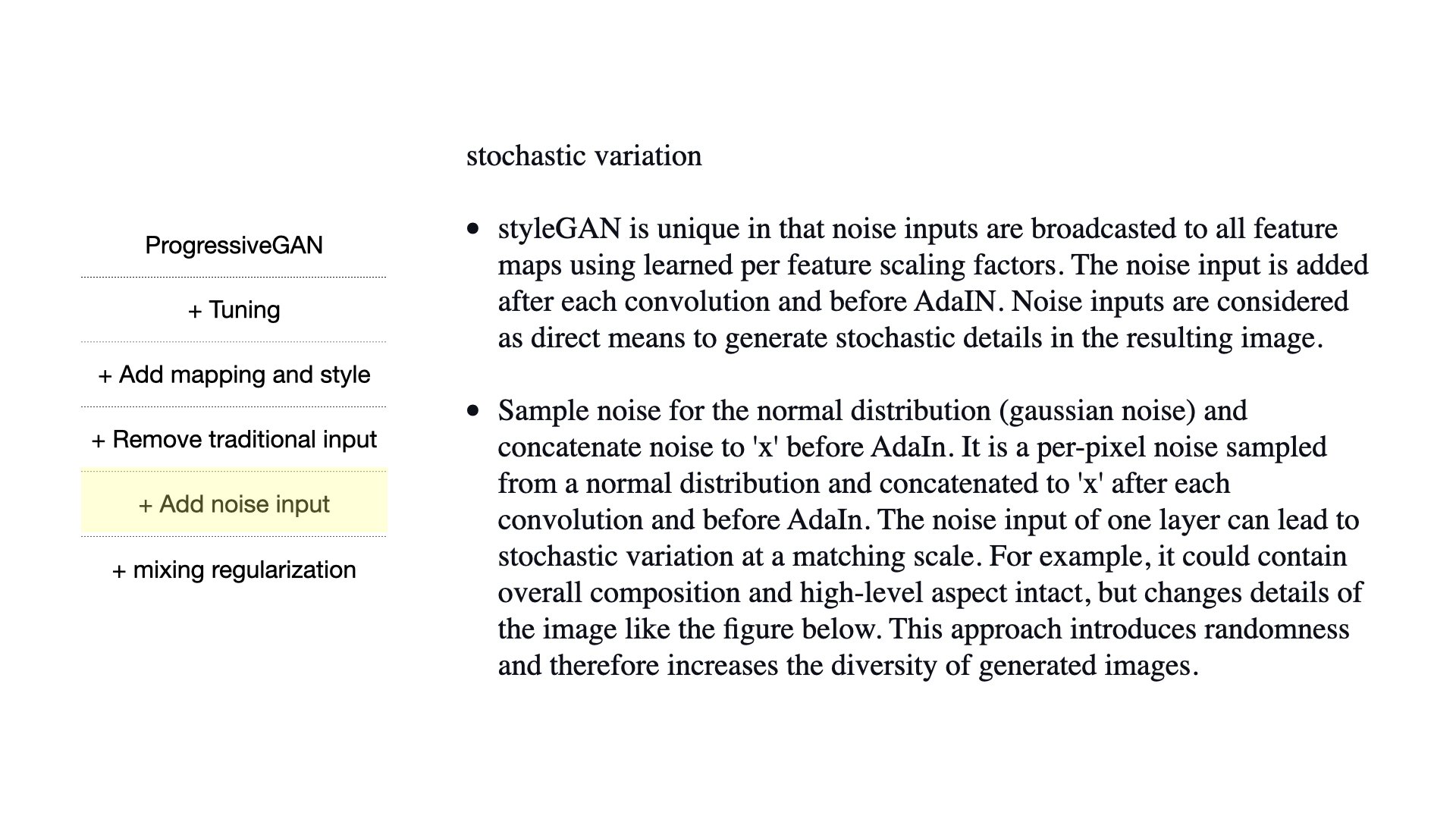
Finally, explicit noise is inserted into the generator. The stochastic variation produces greater fidelity and increased diversity. Single-channel images consisting of uncorrelated Gaussian noise are fed to each layer of the synthesis network to provide a way to generate stochastic details. The noise image is broadcasted to all feature maps using learned per-feature scaling factors and added tlk the output of the corresponding convolution as illustrated in the image below.
Background

Source [7]
Batch Normalization
Batch normalization (BN) accelerate the training of deep neural network by reducing internal covariate shift. It normalizes feature statistics, or the mean and standard deviation for each individual feature channel, across batch size and spatial dimensions. At the training time, BN uses mini-batch statistics while at the inference time it uses popular statistics.
Instance Normalization
The instance normalization (IN) layer computes the mean and the standard deviation across spatial dimensions independently for each channel and each sample.
The conditional instance normalization layer learns a different set of parameters for each style. An interesting thing to note is that the network was shown to generate images in completely different styles by using the same convolutional parameters but different affine parameters in IN layers.
Model Components
Through cards below, I go through each modification authors had made to improve output quality.






StyleGAN2

Early StyleGAN generated images with some artifacts that looked like droplets. The author hypothesized and confirmed that the AdaIN normalization layer produced such artifacts. Overall, improvements over StyleGAN are (and summarized in Table 1):
Generator normalization.
Progressive growing.
Conditioning in the mapping/path length regularizer.
Increasing the capacity of a model that improved overall image quality.
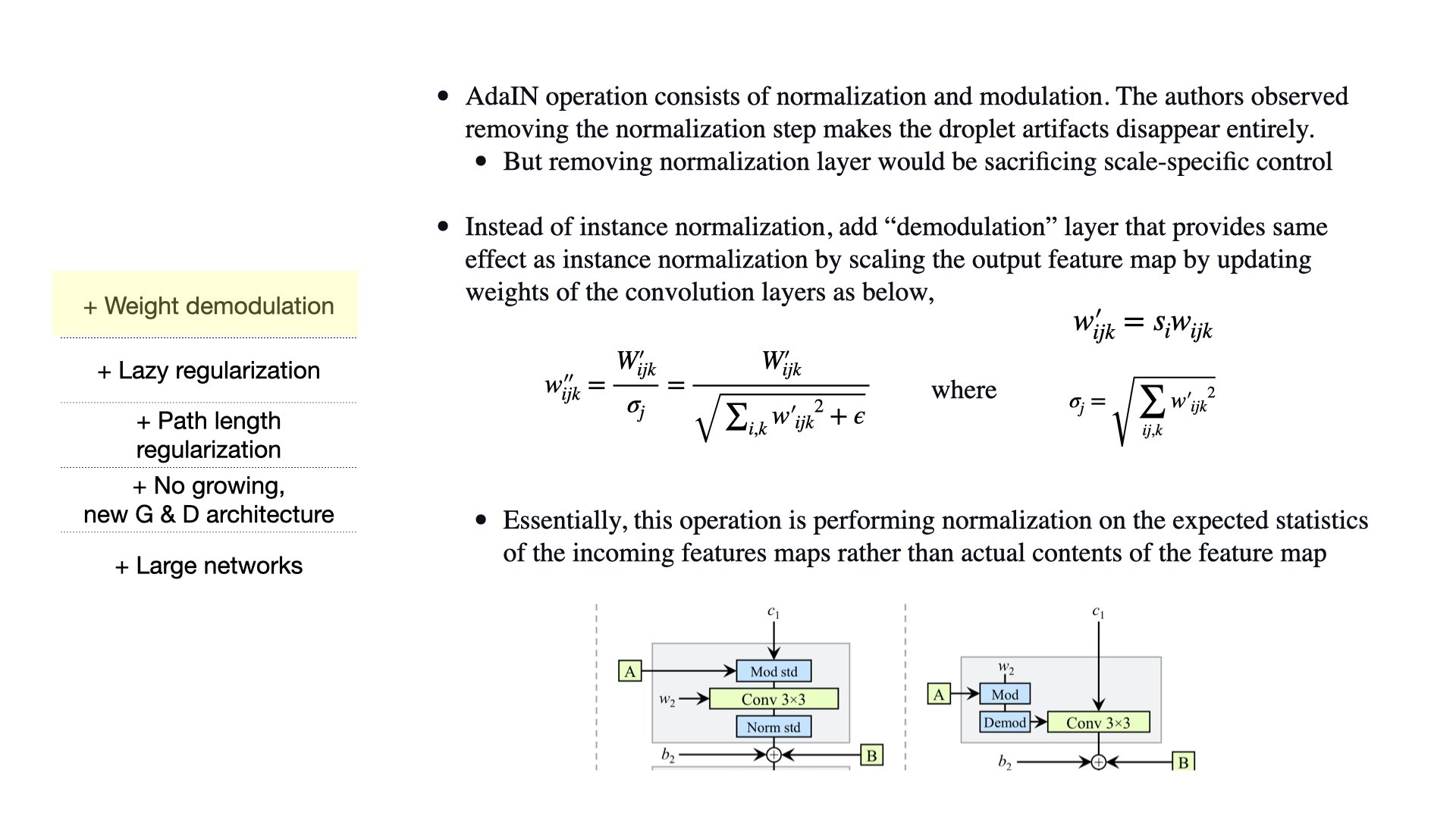
In order to work with changes made in the AdaIN normalization layer, some architects of the model were modified.
The style block in StyleGAN consists of modulation, convolution, and normalization, of which modulation and normalization are two constituent parts of the AdaIN layer. Previously, noise and bias were applied within the style block before normalization operation. However, with the new design, noises and bias are applied outside the style block, in between the two parts of AdaIN operations, on the normalized data. Furthermore, normalization and modulation operate only on the standard deviation and require no mean.
Model Components



StyleGAN3
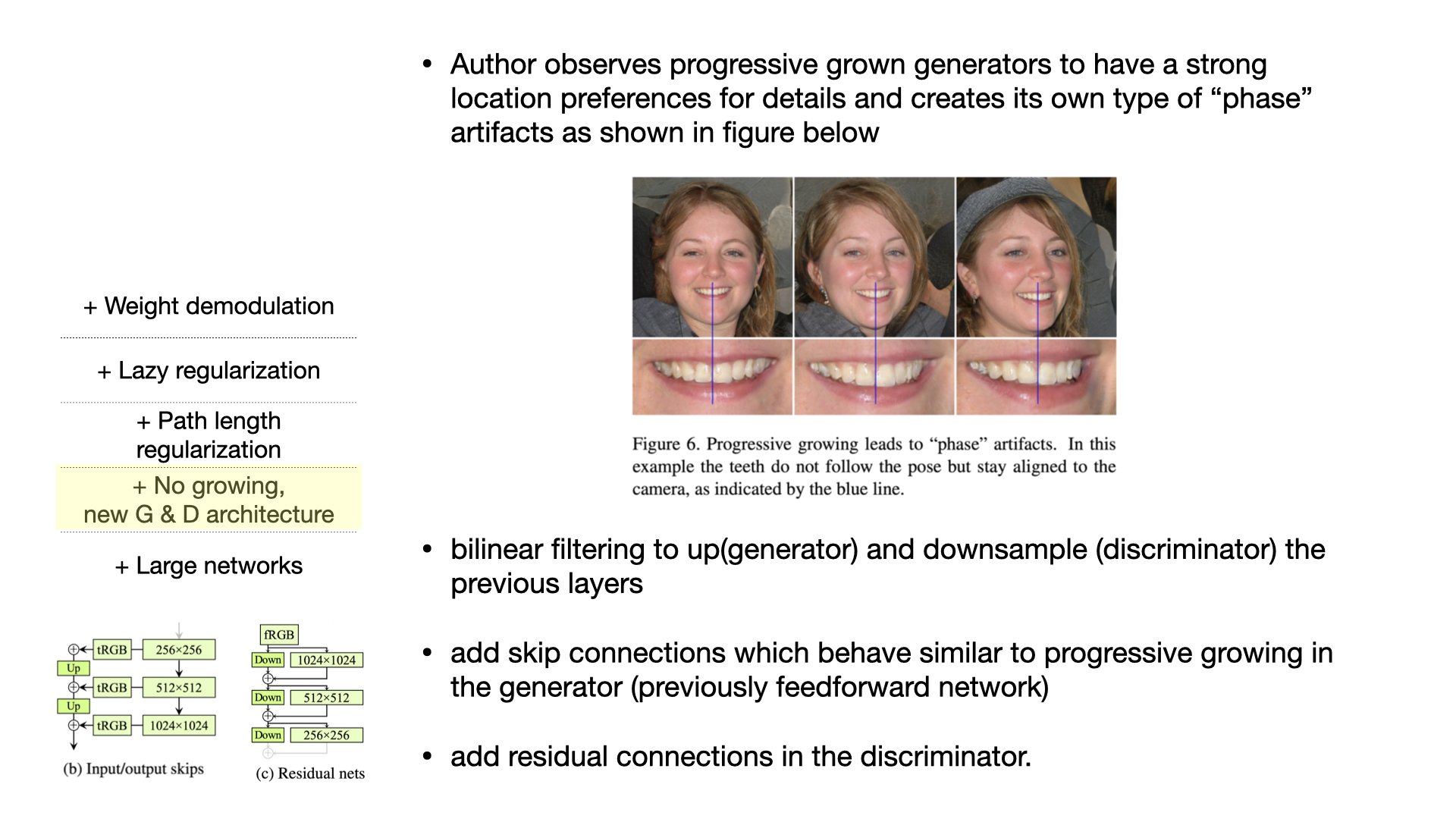
StyleGAN2 architectures do not synthesize images in a natural hierarchical manner, instead, coarse features mainly control the presence of finer features but not their precise positions, much of the fine detail appears to be fixed in pixel coordinates
The authors observed that networks can bypass the ideal hierarchical construction by drawing on 1)unintentional positional references available to the intermediate layers through image borders, 2)per-pixel noise inputs and 3)positional encoding, and 4)aliasing.
Background
Alias in Signal Processing
what is aliasing?
in signal processing, it is defined as an effect that causes different signals to become indistinguishable when sampled ( when higher frequency takes the identity of a lower frequency component... when the sampling rate is too low)
authors hypothesis - two sources for aliasing: 1) faint after-images of the pixel grid resulting from non-ideal upsampling filters (nearest, bilinear, or strided convolutions) 2) the pointwise application of nonlinearities (i.e. ReLU)
alias is most naturally treated in the classical Shannon-Nyquist signal processing framework... a bandlimited functions that eliminate all sources of positional references....for details to be generated equally well regardless of pixel coordinates
Nyquist-Shannon sampling theorem [S3. 51] states that a regularly sampled signal can represent any continuous signal containing frequencies between zero and half of the sampling rate.
Therefore, in CNN, we can consider feature map Z[x] as a discretely sampled representation of a continuous signal z(x). The goal of the generator architecture is to make each layer equivariant with respect to each corresponding continuous signal so that all finer details transform together with the coarser features of a local neighborhood.
Operation f is equivariant with respect to a spatial transformation t of the 2D plane if it commutes with it in the continuous domain.
Model Components









Using RunwayML

StyleGAN is large to compute. For example, the authors took eight V100 GPUs and trained over weeks to get the results. When appropriate hardware is not present, RunwayML is a great tool to get started. Fortunately, the trained weights (pkl) are downloadable and compatible with the open-sourced StyleGAN2/3 repository.
Here is a simple snippet of code to do inference with the trained model from RunwayML:

References
Karras, Tero. Laine, Samuli. Aila, Timo. Style-based Generator Architecture for Generative Adversarial Networks. In Proc. ICLR, 2018.
Karras, Tero. Laine, Samuli. Aittala, Miika. Hellsten, Janne. Lehtinen, Jaakko. Aila, Timo. Analyzing and Improving the Image Quality of StyleGAN. In Proc. NeurlIPS, 2020
Karras, Tero. Aittala, Miika. Laine, Samuli. Harkonen, Erik. Hellsten, Janne. Lehtinen, Jaakko. Aila, Timo. Alias-Free Generative Adversarial Networks. In Proc. NeurIPS, 2021
Haung, Xun. Belongie, Serge. Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization. CoRR, 2017.
https://jonathan-hui.medium.com/gan-stylegan-stylegan2-479bdf256299
https://www.youtube.com/watch?v=BZwUR9hvBPE
https://medium.com/syncedreview/facebook-ai-proposes-group-normalization-alternative-to-batch-normalization-fb0699bffae7